AvatarOne: Monocular 3D Human Animation
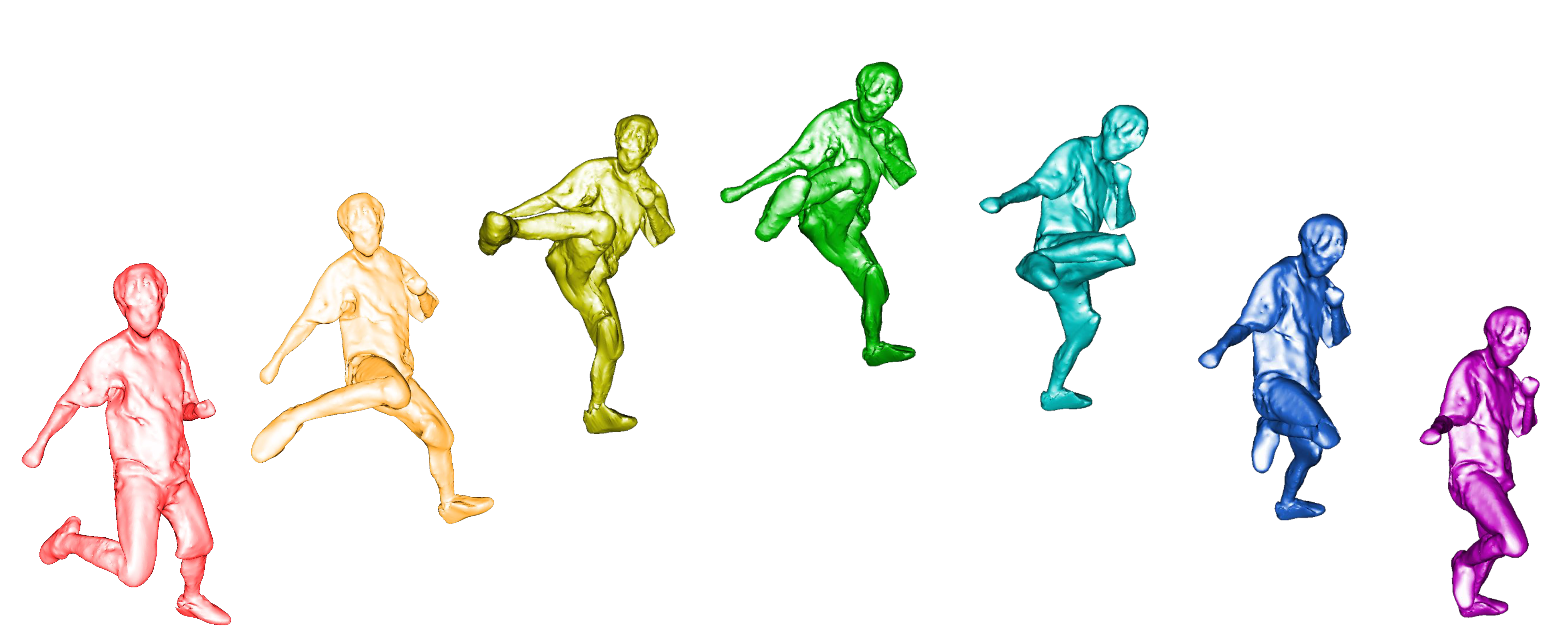
Abstract
Reconstructing realistic human avatars from monocular videos is a challenge that demands intricate modeling of 3D surface and articulation. In this paper, we introduce a comprehensive approach that synergizes three pivotal components: (1) a Signed Distance Field (SDF) representation with volume rendering and grid-based ray sampling to prune empty raysets, enabling efficient 3D reconstruction; (2) faster 3D surface reconstruction through a warmup stage for human surfaces, which ensures detailed modeling of body limbs; and (3) temporally consistent subject-specific forward canonical skinning, which helps in retaining correspondences across frames, all of which can be trained in an end-to-end fashion under 15 minutes. Leveraging warmup and grid-based ray marching, along with a faster voxel-based correspondence search, our model streamlines the computational demands of the problem. We further experiment with different sampling representations to improve ray radiance approximations and obtain a floater free surface. Through rigorous evaluation, we demonstrate that our method is on par with current techniques while offering novel insights and avenues for future research in 3D avatar modeling. This work showcases a fast and robust solution for both surface modeling and novel-view animation.
Method
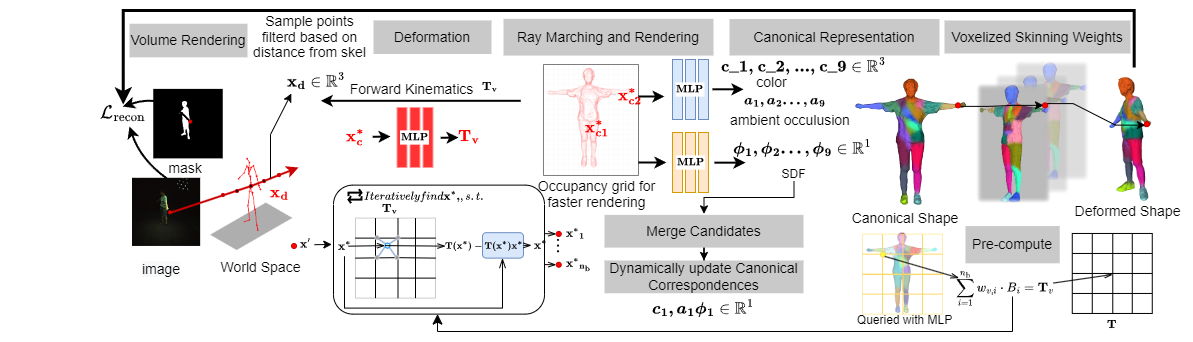
AvatarOne, aims to construct and control a detailed implicit neural avatar in a free view-point and arbitrary novel pose, only using monocular video and known 3D skeleton data We aim to achieve the above goal with the help of three components (1) a canonical representation of the actor (2) a deformation module based on forward skinning (3) a grid-based volumetric rendering with importance sampling via transmittance. The pipeline is illustrated in Figure below. To obtain the animatable model, our method first samples rays from world frame and deforms the points along those rays back to canonical frame via root finding, then query the color and signed distance functions (SDF) values in canonical space. Specifically, we formulate the problem as a pose conditioned implicit signed distance field and texture field in canonical space. The dynamically updated canonical human shape helps optimize the skinning fields as unlike other methods we initialize the skinning weights in canonical space to allow pose generalization Forward Deformation module warps points between canonical space and observation space.
ZJU-MoCap Dataset
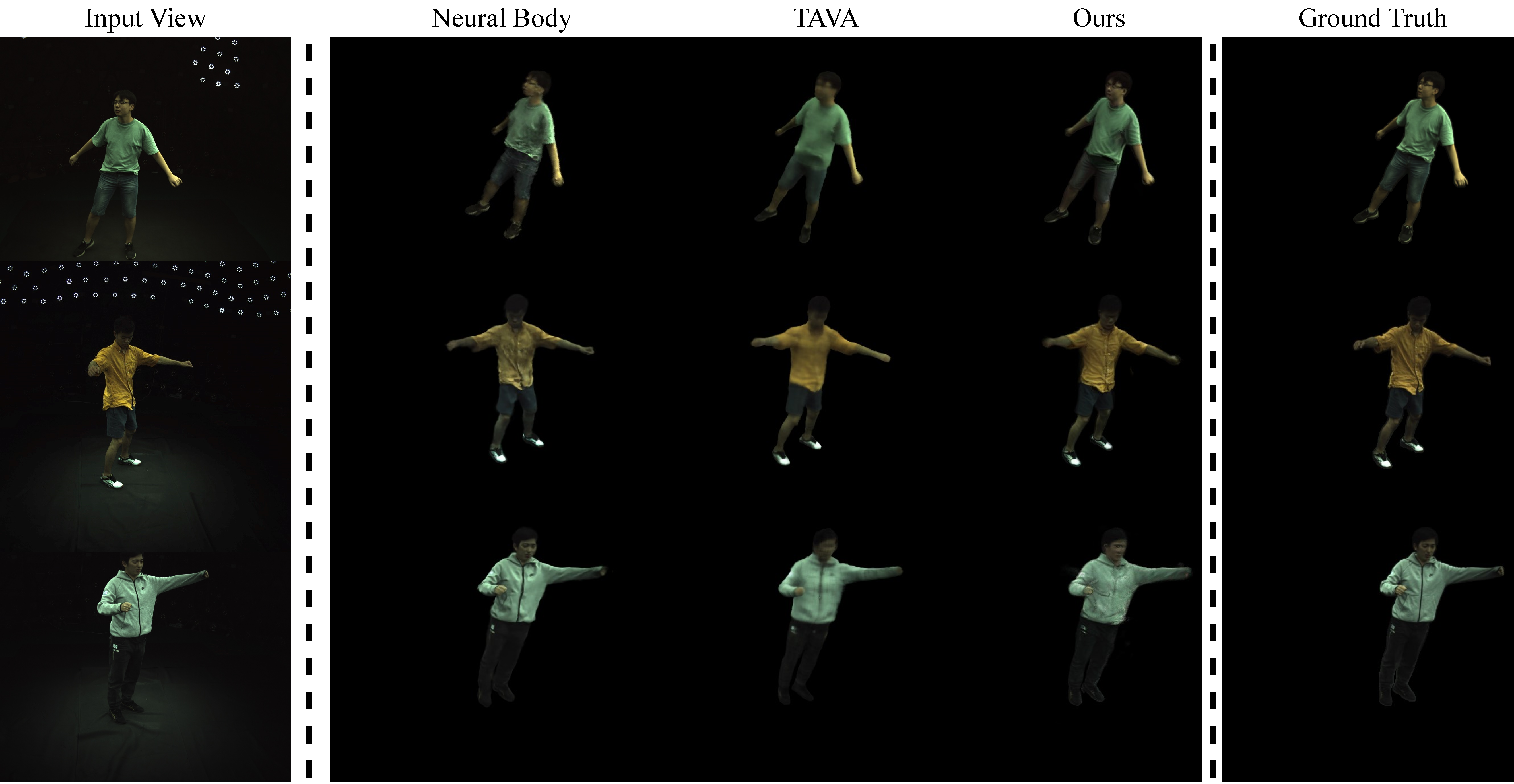
Qualitative result of novel view setting in ZJU-MoCap. We compare the novel view synthesis quality with baseline methods in ZJU-Mocap. Result shows that our method synthesizes more realistic images in novel view.
Some Results
Novel View and Novel Pose Rendering.
Ablation on Warm-up stages (left) with warm-up, (right) without warm-up.
|
Novel Pose from MDM sequences. |
Novel Pose from MDM sequences. |